Home » Data » Dataset use in Stata » Strange Issues w/ Data Formatting from DHS (Data received from DHS seems to be formatted in a way that makes data extraction impossible (longer description below))
| Strange Issues w/ Data Formatting from DHS [message #29033] |
Sat, 13 April 2024 08:17  |
 tednoel
tednoel
Messages: 12
Registered: April 2024
|
Member |
|
|
Hi all, I hope this message finds everyone in good health. I am currently a Master's student in my final semester. I am using DHS data for my thesis. In the interest of simplicity, I will break down the multifaceted problem I am having below. I hope someone might be able to find the time to help me with this strange issue.
Objective: I created an account with DHS and downloaded the data. The goal with the data downloaded is to disaggregate countries into survey "round" (year of survey) and a handful of variables from that round so that I can then merge each respective round with its' shape file (since these change across time for each country). This is important because I will need to merge data via geographic coordinates for my thesis, which is exploring the impact of environmental variables (ex. precipitation rate) on the propensity of marriage under the age of 18 across Sub-Saharan Africa.
Problem: I bulk downloaded survey and geographic data for every African countries where this was available. I decided to start working with one country only so that I could clear any issues with the code before replicating the process for the rest of the countries. To simplify the process, I grouped the bulk downloaded data into its' respective countries and tried to import batches to STATA to work with. The problem begins with the first country I attempted to work with, Tanzania. While I was able to unzip all the files in STATA, this was the furthest I was able to get because what ensued was a bizarre game of smoke and mirrors with the files. For efficiency, I have listed the most major problems below:
1. In the expanded and unzipped files, sometimes I would see a file that does not have a .dta listed, yet, when I would manually go into this file through my Finder just to double check, there would be a .dta file.
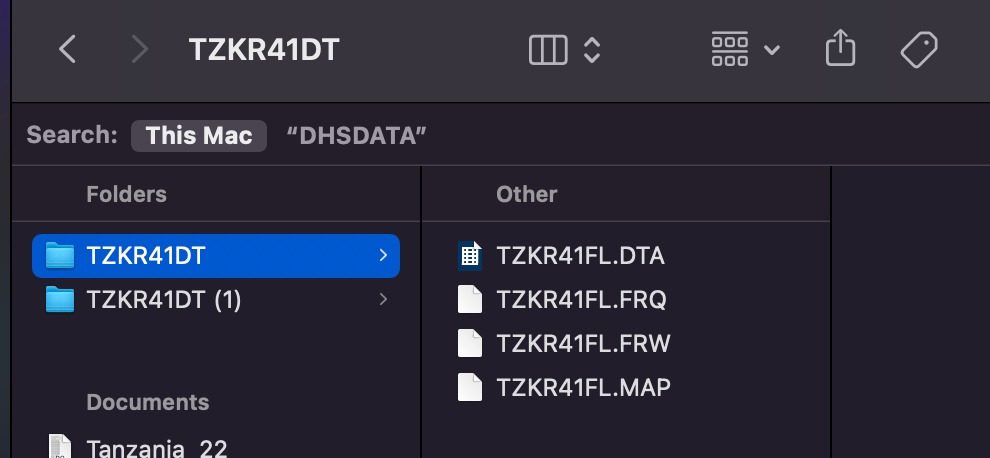
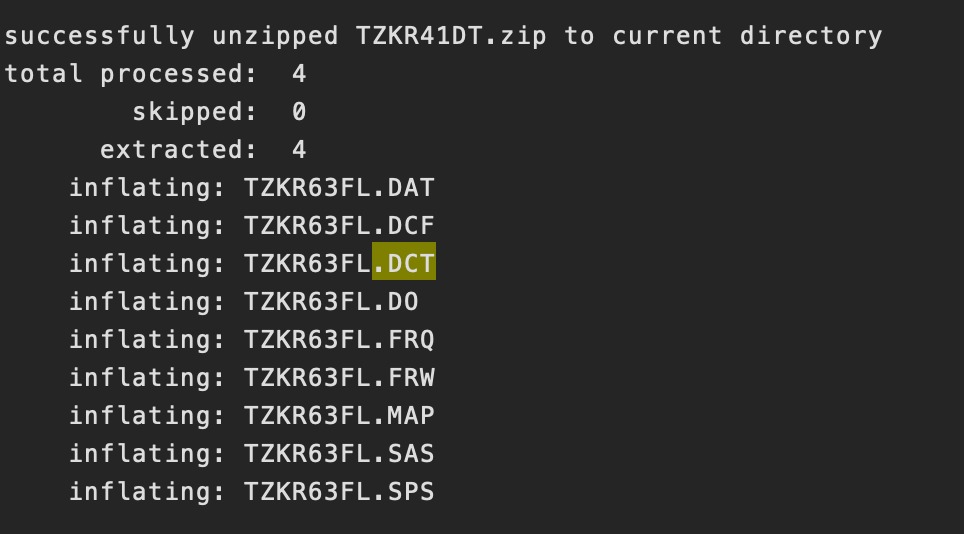
2. There are also situations where an expanded/unzipped file would list its' contents as including a dofile, and when I would go through my Finder to manually ensure that this was there, there would be nothing within the contents of the file.
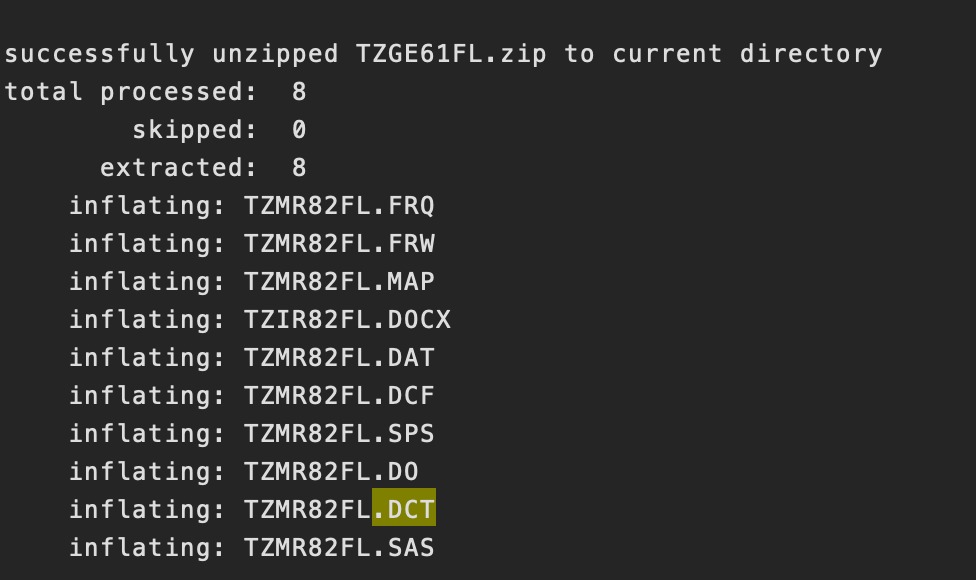
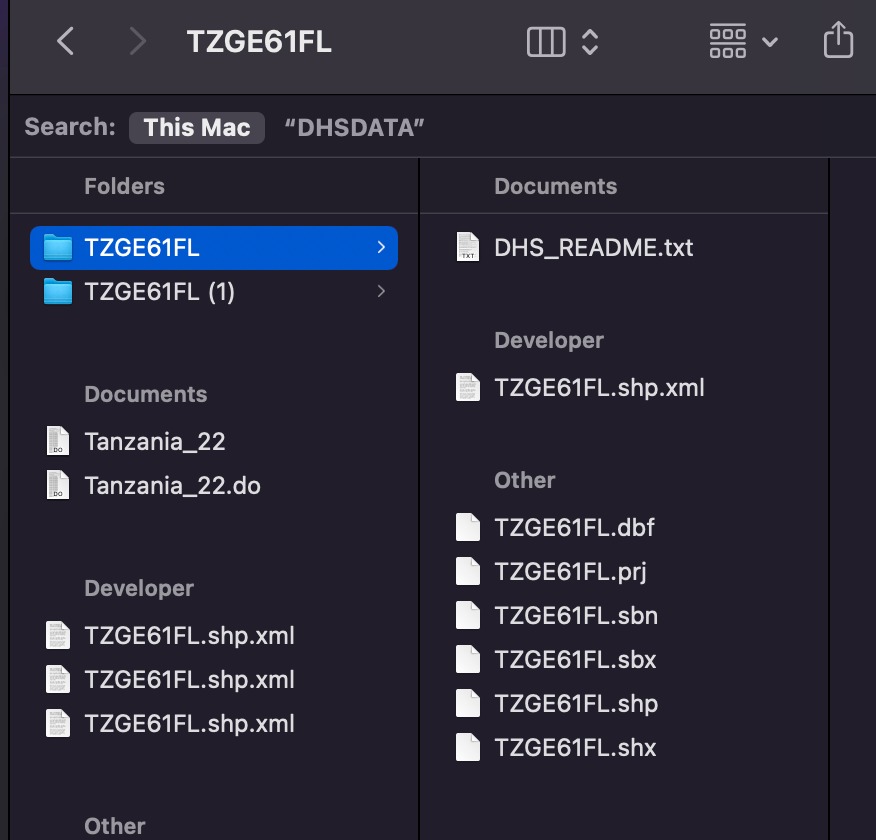
3. Perhaps the largest issue is that it is impossible to run the do file importing the datasets of .dta files because every single path is different inside those files (not possible to write an extraction loop). I made a list of some of the different paths of the .dta files so anyone reading can better understand the issue. This means that I can't get variable lists into STATA.
Below is the code I have used in STATA:
cd "/Users/tbear/Desktop/M2 Thesis/DHSDATA/Tanzania"
capture log close
log using "D:\Niveen Wrking Files\Feps files\FEPS Teaching Files\Year 23-24\MDE\teddi\unzipfiles.log", replace
** [1] Unrar/Unzip all files under the main "DHSDATA" folder
* You need first to run this two lines to make STATA able to extract rar files
shell set path="C:\Program Files\WinRAR"; %path% & unrar e "*"
** some errors resulted while extracting the zip files:
* Zip files under which also contains another zip files - 7 files:
/*
"SNBR70FL"
"SNCR7IDT"
"SNCR7IFL"
"SNCR70DT"
"SNCR70FL"
"SNBR7IFL"
"SNBR70DT"
*/
* they can be extracted manually, then copy their contents zip files back into the main folder "DHSDATA"
* Now unzipping command will work
local path "/Users/tbear/Desktop/M2 Thesis/DHSDATA/Tanzania"
local filelist : dir "`path'" files "*.zip", respectcase
foreach file of local filelist {
unzipfile `file', replace
}
** [2] Extract all the "dta" files in each subfolder under "DHSDATA" folder
* make new folder in which all "dta" files will be saved
global usefile "/Users/tbear/Desktop/M2 Thesis/DHSDATA/Tanzania"
capture mkdir "/Users/tbear/Desktop/M2 Thesis/DHSDATA/Tanzania/Tanzania_dta"
clear
capture set maxvar 100000
local filelist : dir "$usefile" files "*.DTA", respectcase
foreach file of local filelist {
quietly use "`file'", clear
* save each "data" files into the new folder that we made in the first step
save "Tanzania_dta/`file'", replace
}
local filelist : dir "$usefile" files "*.dta", respectcase
foreach file of local filelist {
quietly use "`file'", clear
* save each "data" files into the new folder that we made in the first step
save "Tanzania_dta/`file'", replace
}
capture log close
clear
**********
Thank you so, so much to anyone that might be able to help!!
|
|
|
|
|
|
|
|
|
|
| Re: Strange Issues w/ Data Formatting from DHS [message #29139 is a reply to message #29068] |
Mon, 29 April 2024 08:04  |
tednoel
Messages: 12
Registered: April 2024
|
Member |
|
|
Hi Trevor, THANK YOU SO MUCH. I have been mostly able to solve the problem thanks to the help you have given me. I have one remaining challenge in order to move forward and that is the merging of the different survey data sets for each survey round. So, to be clear, I am interested in controlling for wealth in my proportional hazard. This means that I will have to combine household data and individual data, as indicators for wealth do not exist in the individual recode for Tanzania 1999 (the year I'm starting this data work with). I have read from Tom Pullum in another part of this forum that "it would be virtually impossible to merge them [individual survey] with the HR file, which has households as units. You should use the PR file, which has individual household members as units, rather than the HR file." However, it's not clear to me that wealth is included in the PR file, either. To make matters a bit more confusing, I have seen that this type of merge is possible elsewhere on the internet, for example: https://www.researchgate.net/post/How_can_I_merge_Household_ database_to_Women_data_base_in_the_DHS_data_using_stata
Do you mind clarifying if it is possible to merge household and individual level data? This is the only way I will be able to control for wealth in my proportional hazards analysis. Thank you so much in advance for your time.
|
|
|
|
|
|
|
|
| Re: Strange Issues w/ Data Formatting from DHS [message #29156 is a reply to message #29145] |
Wed, 01 May 2024 12:02 |
tednoel
Messages: 12
Registered: April 2024
|
Member |
|
|
Hi, thanks so much for the response. I've been a bit stumped by this merging process because there are three different datasets (IR, PR, and Wealth Index) that I have to combine and I'm a bit confused as to which one should be my base for merging. I was going to make the IR my base for merging because I've seen code that allows for the renaming of the cluster number, household number, and respondent's line number such as this:
use "/Users/tbear/Desktop/THESIS DATA/Tanzania_1999/Tanzania_1999_dta/TZIR41FL.dta", clear
* keep the variables you want
keep v0*
sort v001 v002 v003
save e:/Users/tbear/Desktop/THESISDATA/Tanzania_1999/Tanzania_199 9_dta/TZIR41FL.dta, replace
* Prepare PR file and merge
use "/Users/tbear/Desktop/THESIS DATA/Tanzania_1999/Tanzania_1999_dta/TZPR41FL.dta", clear
* reduce to women who are eligible for the IR file
keep if hv117==1
* keep the variables you want
keep hv0* sa33 sh*
rename hv001 v001
rename hv002 v002
rename hv003 v003
sort v001 v002 v003
merge v001 v002 v003 using ***Not entirely clear what I should be using here
tab _merge
******
BUT the problem is the wealth index only has the hhid variable that I can use to merge- and the IR file does not have this, only the PR file does. Should I be using the PR file as my base, merging the IR file, and then appending the wealth index?
Thank you so much for all of your help.
|
|
|
|
| Re: Strange Issues w/ Data Formatting from DHS [message #29157 is a reply to message #29156] |
Wed, 01 May 2024 13:01 |
Trevor-DHS
Messages: 808
Registered: January 2013
|
Senior Member |
|
|
Hi
A few notes:
1) It looks like you are opening the IR file, then keeping just a few variables and sorting the file, and then overwriting the original file. This is generally not considered good practice as you are modifying the original file. Generally, you should start with your original file, but save to an interim file with a different name or in a different folder (or both).
2) The naming of your THESISDATA folder seems to vary - in two cases it has a space between THESIS and DATA and in one case it doesn't (this may be a display issue in the user forum as it occasionally puts extra blanks into the text).
3) In terms of the order of merging, I would start by merging the wealth index to the PR file and saving your output to an intermediate file. They both should have hhid so you should be able to merge those without problem. Then merge the info from the PR/wealth data onto the IR file. Below is a rough outline of the process (I haven't tested this, so there may be some bugs - this is just to give you the order of operations):
use TZWIxxxx.dta
sort hhid
save TZWIxxxx.dta, replace
use TZPRxxxx.dta, clear
* keep the variables you want from the PR file
keep hhid hv0* ...
sort hhid
merge m:1 hhid using TZWIxxxx.dta
clonevar v001 = hv001
clonevar v002 = hv002
clonevar v003 = hvidx
sort v001 v002 v003
save TZPRxxxx_temp.dta
use TZIRxxxx.dta, clear
sort v001 v002 v003
merge 1:1 v001 v002 v003 using TZPRxxxx_temp.dta [Updated on: Wed, 01 May 2024 13:02] Report message to a moderator |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Re: Strange Issues w/ Data Formatting from DHS [message #29220 is a reply to message #29170] |
Sun, 12 May 2024 13:54 |
yyumeee
Messages: 2
Registered: May 2024
|
Member |
|
|
Sorry to bother, I was having some problems with some merging on the WI datasets.
My study requires assigning WI values to certain locations, without really needing to connect the WI dataset to the HR dataset, but in order to connect to the GPS Dataset I need the DHSCLUST variable which is obtainable through the HR dataset (var hv001).
I followed the steps detailed in the GitHub document, but R doesnt merge HR and WI datasets, since the whhid in the HR dataset created to merge with the whhid of the WI dataset don't seem to match. The problem looks to be in the fact that thw whhid are written in a slight different way (HR dataset has a blank space between the two numbers, whereas WI does not).
Is there a way to be able to fix this (since I need to perform this task on multiple countries, this needs to be easily iterable)?
Alternatively, if there can be a way to directly merge the WI and GPS datasets without needing the HR dataset, that would be great (I guess the first number of the whhid corresponds to the DHSCLUST, but the problem is the same in that for double digits clusters + double digits households ids there is no blank space to separate the two, so that the whhid 1028 could very well mean both cluster 10 household 28 or cluster 102 household 8).
Thank you in advance.
[Updated on: Sun, 12 May 2024 14:05] Report message to a moderator |
|
|
|
|
|
|
|
| Re: Strange Issues w/ Data Formatting from DHS [message #29384 is a reply to message #29170] |
Tue, 11 June 2024 06:07 |
tednoel
Messages: 12
Registered: April 2024
|
Member |
|
|
Hi Trevor! Hope you are well. I have one last question (about to turn my thesis in :D) I want to combine multiple survey rounds to do one meta analysis of the proportional hazard rate of child marriage in response to exposure to flooding... But I've read so many conflicting opinions with respect to whether or not weights are even necessary when doing this (for example: https://userforum.dhsprogram.com/index.php?t=msg&goto=81 &S=Google). That being said, even for the summary statistics I will run, I know official DHS guidance is that population weights should be used, but how do I combine population weights into one weight for summary statistics? I'm interested in running summary statistics for the DHS surveys from Tanzania in 1999, 2010, 2015-16, and 2022; Kenya in 2003, 2008, 2014, and 2022; Zambia in 2007, 2013, and 2018; and Malawi for the years of 2000, 2004, 2010, and 2015. I feel like I would need a different sampling weight for each round? A bit confused on this... also confused as to whether I would need sampling weights for a combined hazards analysis. Below is the code to my cox proportional hazards model:
* Generate event indicator for marriage by age 18
generate married_by18 = (v511 < 18) & !missing(v511)
label variable married_by18 "Married by age 18"
generate married_by15 = (v511 <= 15) & !missing(v511)
label variable married_by15 "Married by age 15"
* Generate time-to-event or censoring
generate current_age = hv007 - v010
label variable current_age "Age at the time of study"
generate time = cond(married_by18 == 1, v511, current_age)
label variable time "Time to marriage by age 18 or censoring"
* Set the survival data
stset time, failure(married_by18)
* Run Cox regression (example with other covariates)
stcox flood_exposure rural_dummy sexhh_dummy primary_education low_wealth _Iyear
any help you could provide would be incredibly, incredibly appreciated!! thanks so much in advance
|
|
|
|
|
|
|
|
| Re: Strange Issues w/ Data Formatting from DHS [message #29392 is a reply to message #29389] |
Tue, 11 June 2024 14:12 |
Trevor-DHS
Messages: 808
Registered: January 2013
|
Senior Member |
|
|
It is not that the date of the household interview is different (although it can be on occasion) - usually the household interview is the same day as the individual interview, or the individual interview is the next day. The issue is that the calculation of age is wrong about half the time if you just subtract year of birth from year of interview. For example, someone born in 2000 and interviewed in 2004 could be either 23 or 24, depending on the day and month of birth and the day and month of interview. The simple calculation would give you 24, but about half of the cases would actually be 23, so it is much better to use the actual reported age.
For the issue of getting v012 into your data files, I think your approach of creating a separate file and then merging it in should work fine.
|
|
|
|
Goto Forum:
Current Time: Fri Dec 12 15:29:03 Coordinated Universal Time 2025
|
 Members
Members Search
Search Help
Help Register
Register Login
Login Home
Home







")
