Home » Data » Merging data files » Duplicates in IR file when merging
| Duplicates in IR file when merging [message #8652] |
Tue, 24 November 2015 20:25  |
 nholla
nholla
Messages: 13
Registered: May 2015
|
Member |
|
|
Hi DHS,
I'm trying to merge the individual to the birth recode files for several countries using the following code in stata, where the birth recode is the "master" file:
merge m:1 v001 v002 v003 using "filename", gen(ir)
However, I'm getting a "does not uniquely identify observations in the using dataset" error. I observed duplicates in terms of v001 v002 v003 for the following files:
Mali 2001
Niger 2000
Niger 1992
Senegal 1998
Senegal 1986
Nigeria 1990
Can multiple women have the same "respondent" in the IR file? If so, how could this occur? For a few of them, I was able to find an additional identifier (such as sconces or snumber). For those surveys I can't find an additional identifier, should I be merging on caseid?
Thanks!
|
|
|
|
| Re: Duplicates in IR file when merging [message #8688 is a reply to message #8652] |
Wed, 02 December 2015 08:14  |
Bridgette-DHS
Messages: 3230
Registered: February 2013
|
Senior Member |
|
|
Following is a response from Senior DHS Stata Specialist, Tom Pullum:
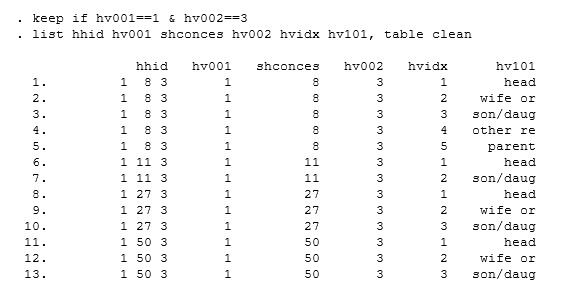
For these surveys, unfortunately, another variable is required to identify households within households. If you look at hhid in most surveys, you will see that it is constructed by combining hv001 and hv002. In the surveys you listed, however, hhid includes a third variable. In the HR file for the Mali 2001 survey (MLHR41FL.dta), for example, there are four households with hv001=1 and hv002=3. For these sub-households, there is another variable that takes the values 8, 11, 27, and 50 that has been incorporated into hhid. In the Mali 2001 survey, this is a survey-specific household variable (prefix sh) called shconces.
If you look at the household questionnaire at the back of the main report on this survey, the top of the first page, you will see "numero de grappe", which is French for "cluster number", and right under that "numero de concession". So--for this survey you need to include shconces every time you sort and merge. In the other surveys you will have to hunt for that variable. There is probably a list somewhere of the name of this extra id variable--I don't think it is always called shconces.
I believe this code is not included in surveys more recent than the ones you listed. For example, looking at the Mali 2006 survey, I see that "numero de concession" is included on the household questionnaire, but hhid is constructed solely from hv001 and hv002. The easiest way to check whether this is an issue is to open the HR file and then enter the following:
gen n=1
collapse (sum) n, by(hv001 hv002)
tab n
You have a household id problem if "tab n" produces more values of n than n=1. If you do not have an HR file, you can use the PR file, enter "keep if hvidx==1", and then enter those three lines.
Using the full id for these surveys will be important if you are merging. It could be relevant if you are using the relation to head code (hv101). I will list some variables for the 13 cases in the Mali 2001 file with hv001=1 and hv002=3. For many kinds of analysis it is irrelevant. Good luck.
|
|
|
|
|
|
| Re: Duplicates in IR file when merging [message #8914 is a reply to message #8784] |
Wed, 13 January 2016 08:18 |
Bridgette-DHS
Messages: 3230
Registered: February 2013
|
Senior Member |
|
|
Following is a response from Senior DHS Stata Specialist, Tom Pullum:
If you list out caseid and v003 for the first few cases in the IR file, and list out hhid for the first few cases in the HR file, you will see that caseid is simply a combination of hhid and v003.
Both caseid and hhid are character strings (str15 and str12, respectively); v003 is numeric.
Before you do the merge, when you open the IR file, use this line: gen hhid=substr(caseid,1,12). Then merge with the IR file using hhid. I think this will work for what you want to do, but let me know if it does not.
|
|
|
|
Goto Forum:
Current Time: Thu Dec 25 02:41:41 Coordinated Universal Time 2025
|
 Members
Members Search
Search Help
Help Register
Register Login
Login Home
Home






")
