Home » Data » Weighting data » How to Weight Data in R
| How to Weight Data in R [message #179] |
Thu, 21 March 2013 16:17  |
 Jewel
Jewel
Messages: 1
Registered: March 2013
Location: United States
|
Member |
|
|
I am trying to use the package "Survey" in R to do a DHS analysis, but I want to be sure that I am setting up the weights properly.
My general code is as follows:
weight<-mydhsdata$v005/1000000
> data <- svydesign(id = mydhsdata$caseid, strata=mydhsdata$v021,
+ weights = weight,
+ data=mydhsdata)
If anyone has any insights on how to set up the dataset in R, I would appreciate the help!
|
|
|
|
| Re: How to Weight Data in R [message #198 is a reply to message #179] |
Mon, 25 March 2013 10:52  |
Bridgette-DHS
Messages: 3230
Registered: February 2013
|
Senior Member |
|
|
Here is a response to your question, from one of our DHS experts, Tom Pullum.
We cannot offer much support for R.
Yes, V005 is always the weight variable.
The psu or cluster variable is V001 or V021. These are generally exactly the same--that is, they are duplicates. If in any doubt, use V001. There will typically be several hundred clusterS. Your code used v021 as the stratification variable, and that would be a mistake.
The stratification variable is not always clearly identified, but in virtually all surveys the strata are the combinations of region (the first subnational unit) and urban/rural (always v025). Region and strata are usually given by v022, v023, or v024. (v101 is a duplicate of region.) Take a quick look at those three variables. There will typically be about twice as many strata as regions--often one less than twice as many, because the capital region may be completely urban. The number of strata will typically be in the rage of 20 to 40.
If you have difficulty identifying the stratification variable for a specific survey, please contact DHS.
I hope this helps.
Bridgette-DHS
|
|
|
|
| Re: How to Weight Data in R [message #706 is a reply to message #179] |
Thu, 22 August 2013 16:13 |
onetwo
Messages: 1
Registered: August 2013
Location: United States
|
Member |
|
|
Hi Jewel
I can't unfortunately answer to your question but since you seem to have used DHS data in R, I just wanted to ask how you manage to read the data. I have no conventional stat package in my computer so I have to totally rely on R. When I write the following code to simply read the stata data, I got errors messages:
> mydata <- read.dta("c:/Births/CDBR50DT/CDBR50FL.dta")
There were 50 or more warnings (use warnings() to see the first 50)
> warnings ()
Warning messages:
1: In `levels<-`(`*tmp*`, value = if (nl == nL) as.character(labels) else paste0(labels, ... :
duplicated levels in factors are deprecated
...
Thanks for helping if possible!
And if anybody else can help, I'll be glad!
|
|
|
|
| Re: How to Weight Data in R [message #770 is a reply to message #179] |
Sat, 14 September 2013 11:02 |
Trevor-DHS
Messages: 808
Registered: January 2013
|
Senior Member |
|
|
To follow up on how to weight the data in R and use the sample design, I use the following:
DHSdesign <- svydesign(id = mydata$v021, strata=mydata$v022, weights = mydata$v005/1000000, data=mydata)
Note that the id above is the cluster id (v021), not the caseid. The strata are given by v022, but as Tom Pullum noted in his reply (posted by Bridgette), you need to check the stratification to use. Sometimes v022 gives the stratification to use, sometimes v023, and sometimes neither are set and you have to create it from v024 (region) and v025 (urban/rural). See the sampling design appendix in the DHS final reports for each survey for information on the stratification used in the survey.
Once you have set up the design, you can use it as follows:
svymean(~v201, DHSdesign)
cv(svymean(~v201, DHSdesign))
confint(svymean(~v201, DHSdesign))
svymean(~factor(v025), DHSdesign)
Regards. Trevor
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Re: How to Weight Data in R [message #17444 is a reply to message #17443] |
Tue, 19 March 2019 10:52 |
Trevor-DHS
Messages: 808
Registered: January 2013
|
Senior Member |
|
|
It looks like it doesn't like the parameter id=, but wants ids=. Try
DHSdesign <- svydesign(ids = stata.file$v021, strata=stata.file$v022, weights = stata.file$v005/1000000, data=stata.file)
I just tested on my system, though, and it accepts id=, so I'm not sure that is your problem.
Also look at how the variable names are spelled. Usually they are all lower case, but you have V005 with a capital letter in your post, but this should probably be v005 (as I used it above). I think this is maybe your source of error.
|
|
|
|
|
|
|
|
|
|
| Re: How to Weight Data in R [message #19681 is a reply to message #770] |
Sat, 01 August 2020 06:39 |
Sajhama
Messages: 28
Registered: July 2017
|
Member |
|
|
Hello there,
I have been trying to use R for DHS, otherwise was a SPSS person. I am familiar with R commander to be more precise.
While trying to weigh data or use complex sample, the following command that you have written in your above messages didn't showed weighted data for me. The weighted and non weighted were same. I think the code have gone wrong somewhere. Please let me know on this for improvement. Thank you in advance.
Below is the code and have attached screenshot of both the weighted and unweighted data. Look forward.
DHSdesign <- svydesign(ids = DHS2016Nepal$HV021, strata=DHS2016Nepal$HV022, weights = DHS2016Nepal$HV005/1000000, data=DHS2016Nepal).... is for complex sample and
command for unweighted is below
local({
.Table <- with(DHS2016Nepal, table(HV025))
cat("\ncounts:\n")
print(.Table)
cat("\npercentages:\n")
print(round(100*.Table/sum(.Table), 2))
})
command for weighted is below:
local({
.Table <- with(DHS2016Nepal, table(HV025), DHSdesign)
cat("\ncounts:\n")
print(.Table)
cat("\npercentages:\n")
print(round(100*.Table/sum(.Table), 2))
})
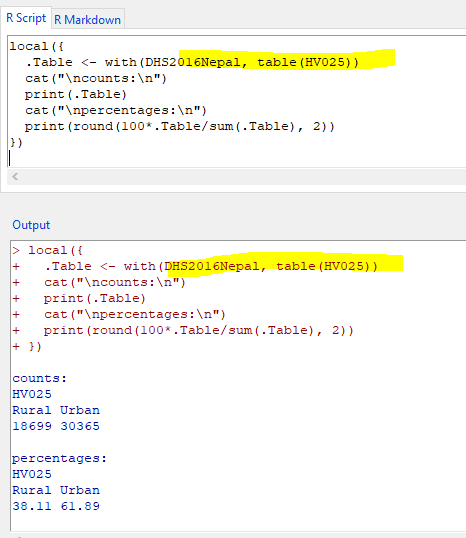
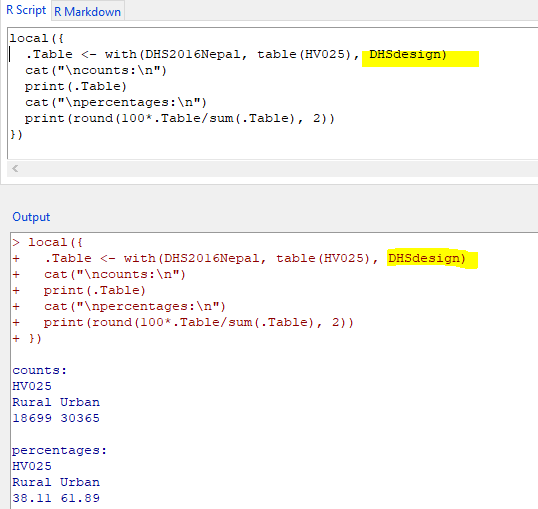
[Updated on: Sat, 01 August 2020 06:44] Report message to a moderator |
|
|
|
| Re: How to Weight Data in R [message #19705 is a reply to message #19681] |
Tue, 04 August 2020 15:39 |
Bridgette-DHS
Messages: 3230
Registered: February 2013
|
Senior Member |
|
|
Following is a response from DHS Senior Sampling Specialist, Mahmoud Elkasabi:
I do not see any problem with the svydesign function. I believe the problem is with the with function you are using for the weights estimates. I don't think you can use the svydesign with the with function. You should use the svy functions from the survey package. For example, for your analysis I would imagine a function as follows:
prop.table(svytable(~HV025,design=DHSdesign))
|
|
|
|
Goto Forum:
Current Time: Wed Jan 7 15:24:51 Coordinated Universal Time 2026
|
 Members
Members Search
Search Help
Help Register
Register Login
Login Home
Home






")
